儘管大型語言模型已經透過大量數據進行訓練,它們還是存在一些局限。例如,它們無法即時獲取最新資訊,或是在某些專業領域的知識仍不夠完整。為了彌補這些不足,我們可以採取兩種方法。
第一種方法是透過載入外部文件或資料,讓AI在生成回答前能進行檢索。這就是今天要討論的部分。
舉例來說,如果我有一份社團活動的成果報告word檔,希望Ollama在回答相關問題時能夠引用其中的內容,我可以將這份文件上傳給它。如此一來,Ollama就會先檢索上傳的資料,並提供更精準的回答。
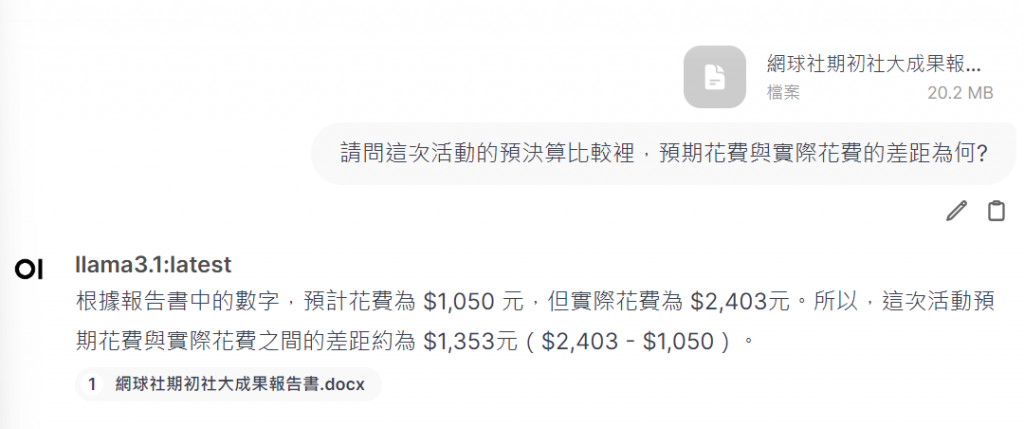
不過,這種方法有一個缺點,就是因為需要經過檢索再生成回應,所以可能會稍微延長回應時間。而且每次都需要手動上傳文件,對使用者來說也會略顯不便。因此,明天我們將介紹另一種方法——模型微調,來進一步解決這些問題。


 iThome鐵人賽
iThome鐵人賽